DW
Data Warehouse 의 의미로 큰의미로 방대한 조직 내 분산 운영시 각각의 데이터 베이스 시스템을 통합 관리 합니다. 그렇기에 효율적인 의사 결정을 위한 기초를 제공하는 실무적인 활용방법으로써 사용됩니다.
데이터 웨어하우스는 하드웨어와 관리 소프트웨어,추출/변환/정렬 도구, 메타 데이터 등 최종 사용자로 하여금 활용 도구 등으로써 구성되어 있습니다.
데이터 웨어하우스의 성질
데이터 웨어하우스는 다음과 같은 특성을 가집니다.
주제 지향적 (subjectoriented)
통합적 (integrated)
시계열적(timevarient)
비휘발적(nonvolatile)
기술이 변화함에 따라 데이터를 저장하고 관리 분석하는 방법중 하나로 사용되는 개념인 DW는 대형 메인 프레임 등 기존의 플랫폼으로는 시간과 비용의 제약이 있었지만 병렬 서버의 등장과 자기 디스크 장치의 대용량화,저가격화로 인해서 가능하게 되었습니다. 병렬 서버를 사용해 여러 복수 프로세스로 처리 함으로써 높은 속도의 검색을 할 수 있기 때문입니다.
데이터 웨어하우스의 작동방식
조회 쿼리를 지속적으로 요청할 경우 정보시스템의 부하가 일어 날 수 있습니다.(운영,기간계 기스템 등) 그렇기에 운영하는 DB에서 DB서버에 무리 하지 않을때 따로 빼내서 분석만을 위한 DB에 저장을 하게 됩니다. 데이터 웨어하우스는 이러한 용도로 ㅈ사용됩니다.
여러 소스의 데이터를 통합.
과거 데이터를 분석.
데이터 품질, 일관성 및 정확성 제공.
트랜잭션 데이터베이스와 분석 처리를 분리해 두 시스템 모두의 성능을 향상.
데이터레이크에서 웨어하우스까지
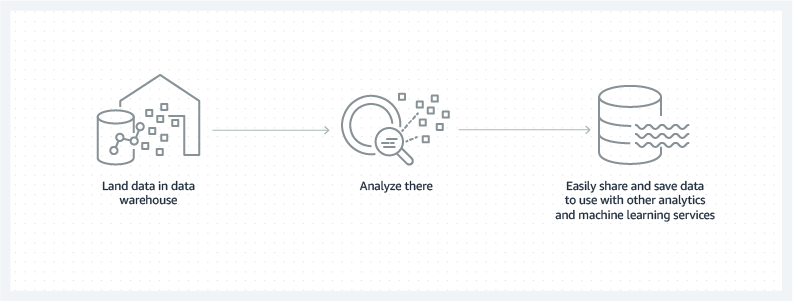
데이터베이스나 레이크 에서 데이터를 연결하고 준비하면 웨어하우스로 이동한 후 보고를 수행합니다. 아래 아래 사진을 참고해 그림으로 보도록 하겠습니다.

또한 데이터 웨어하우스 에서 데이터를 연결하고 분석 후에 데이터를 공유하여 머신러닝 같은 기계 학습서비스와 함께 적용됩니다.
DW 와 DataMart
데이터 마트는 금융, 마케팅 영역 이나 특정 팀의 사업 요구를 만족시키기 위한 데이터 웨어 하우스 입니다. 규모는 데이터 웨어하우스에 비해서 더 작지만 집중적이며 사용자의 커뮤니티에 잘 맞는 데이터를 포함 시킬 수 있습니다. 데이터 마트는 데이터 웨어하우스에 속하는 소개념 이라고 볼 수 있습니다.
범위
함께 통합된 중앙 집중식의 여러 주제 영역
분산된 특정 주제 영역
사용자
전사적
단일 커뮤니티 또는 부서
데이터 원본
여러 소스
단일 또는 몇 개의 소스,또는 데이터 웨어하우스에 이미 수집된 데이터의 일부
크기
대규모이며 수백 기가바이트에서 페타바이트에
이를 수 있음 소규모이며 대개 최대 수십 기가바이트에 이름
설계
하향식
상향식
데이터 세부 정보
완전한,상세 데이터
요약된 데이터를 포함할 수 있음
Last updated