빅데이터 아키텍처
초기의 빅데이터 플랫폼
초기의 빅데이터 플랫폼은 끝에서 끝으로 각 서비스 로부터 데이터를 배치로 모았습니다. 데이터를 배치로 모으는 구조는 유연하지 못하며 실시간으로 생성되는 데이터들에 대한 인사이트를 서비스 에 빠르게 전달하지 못하였습니다. 원천 데이터로부터 파생된 데이터의 로그를 파악하기 힘들었고, 계속되는 데이터의 가공으로 데이터가 파편화 되면서 데이터 표준을 지키기 어려웠습니다.
람다 아키텍처
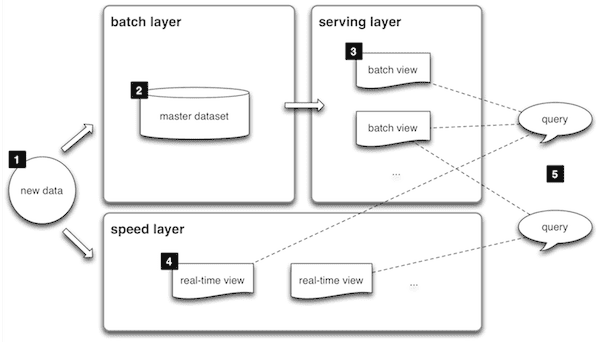
람다아키텍처는 3가지 레이어로 나뉩니다.
배치레이어
서빙레이어
스피드레이어
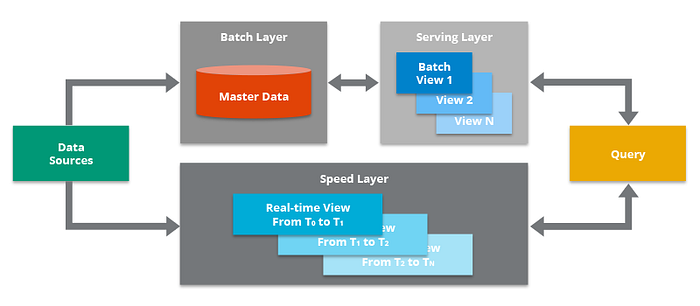
배치레이어는 배치 데이터를 모아서 특정 시간, 타이밍 마다 일괄 처리합니다.
서빙레이어는 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도로 사용합니다.
스피드레이어는 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도로 사용합니다.
데이터를 처리하는 레이어와 실시간 처리를 담당하는 레이어를 분리한 람다 아키텍처는 데이터를 처리방식에서 명확이 구분이 되지만 레이어가 2개로 나뉘고, 데이터를 융합 처리할 때 또한 유연하지 못한 파이프 라인을 생성해야 한다는 점 떄문에 한계의 상황에 부딪일 때가 많았습니다.
카파 아키텍처
람다 아키텍처의 단점을 해소하기 위해 제이 크렙스가 카파 아키텍처를 제안했습니다. 람다 아키텍처에서 단점으로 꼽혔던 로직의 파편화, 디버깅, 배포, 운영 분리에 대한 이슈를 제거하기 위해 배치 레이어를 제거한 카파 아키텍처는 스피드 레이어에서 모두 처리할 수 있으므로 엔지니어들은 효율적으로 개발 및 운영을 할 수 있게되었 습니다.
로그는 배치 데이터를 스트림으로 표현하기에 적합합니다. 일반적으로 데이터 플랫폼에서 배치 데이터를 표현할 때는 각 시점의 전체 데이터를 백업한 스냅샨 데이터를 뜻했습니다. 그러나 배치 데이터를 로그로 표현 할때 각 시점의 배치 데이터의 변환기록을 시간 순서대로 기록함으로써 모든 스냅샷 데이터를 저장하지 않고도 배치 데이터를 표현 할 수 있게 되었습니다.
배치,스트림 데이터
배치 와 스트림 차이
- 한정된 데이터 처리 - 대규모 배치 데이터를 위한 분산 처리 - 분,시간, 일단위 처리를 위한 지연발생 - 복잡한 키 조인 수행
- 무한 데이터 처리 - 지속적으로 들어오는 데이터를 위한 분산 처리 수행 - 분 단위 이하 지연 발생 -단순한 키 조인 수행
배치 데이터를 처리하는 방식(하둡)
스트림 데이터를 배치로 사용하는 방식(카프카)
스트림 데이터를 배치 데이터로 사용하는 방식은 로그발생시 시간을 남겨 적재된 데이터를 배치로 처리 할 수 있도록 합니다. 이 시간을 기준으로 기간을 설정하고 데이터를 가져온다면 매치로 처리 할 수 있게됩니다. 카프카는 로그에 시간을 남기기 때문에 이런 방식의 처리가 가능합니다.
카프카 비전
카파 아키텍처는 데이터를 사용하는 고객을 위해 스트림 데이터를 서빙레이어에 저장하는 방식입니다. 카프카 창시자 제이 크랩스는 이러한 방식에서 서빙레이어를 제거하고 데이터를 오랜기간 저장 하고 보관 할수 있다면 서빙레이어의 목적도 사라지기 때문에 운영 및 리소스의 낭비를 더욱 최소화 시킬 수 있는 스트리밍 데이터 레이크 방식을 제안 했습니다. 카프카에 이러한 미래 지향적이고, 효율적 방식의 아키텍처 개념에서 통합은 큰 비전이라고 생각합니다.
Last updated